Introduction
When you first start programming you’ll often hear that you should always version control your code.
You’ll also hear words thrown around such as Git, GitHub, GitLab and similar services.
If you’re not sure what the difference is I’ll be breaking it down in this post, but first a high level overview of the difference between them:
Git is an open source distributed version control system (DVCS) that allows developers to work on the same project from anywhere and even if they’re offline. GitHub, GitLab and their alternatives are cloud services that provide remote hosting of Git repositories, as well as features such as task management, wikis, CI and more.
Let’s break it down further.
What is Git and why is it used?
Git is an open source (free to use) distributed version control system developed in 2005 by the Linux development community headed by Linus Torvald.
Developers use it to track and make changes to a codebase.
At any time a developer can look back through the history of the changes to figure out when something was changed, why it was changed, or to revert to a previous version.
It can be used both for small projects consisting only of a few lines of code to very large projects such as the Linux kernel project which has over 27 million lines of code and over 1 million commits.
Distributed vs non-distributed version control systems
As mentioned Git is a distributed version control system.
This means that all developers working on a project have access to the complete codebase. They don’t need to be continuously connected to a central repository (aka repo), or have a server running to use Git.
The version they’re working on will have all the history of changes up till that point, and they can synchronize at any time to fetch newer changes.
Key benefits of using Git
1) It generally only adds data, which means that change history is retained
Think of it like this:
Let’s say you have a folder, you save a file to it, you then delete that file and empty your recycle bin.
You’ve just lost that data and can’t revert your change (technically you can still recover it but let’s keep it simple for this example).
Using Git however this would happen instead:
- You add the file to your folder and commit it (“save” it). This adds more data to your Git history.
- You delete the file and commit the change again. The file looks like it’s deleted as you can’t see it in the folder however Git has saved the delete action as an additional step in its history.
- You can now look back through your history or recover that file if you need to.
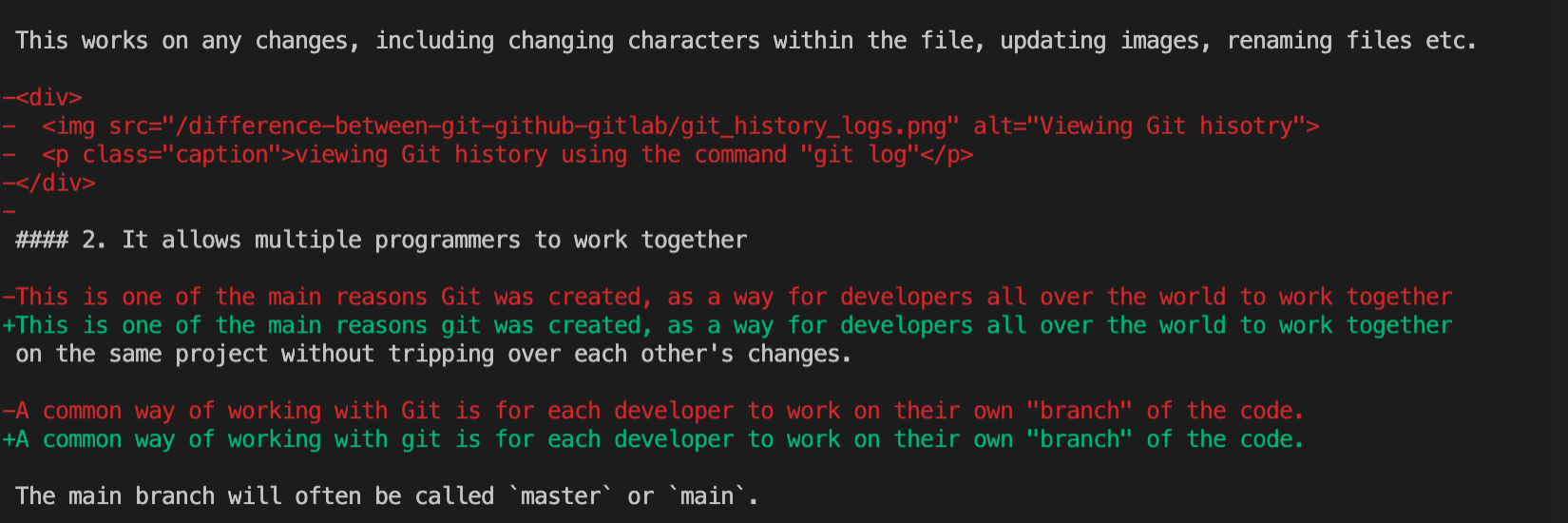
This works on any changes, including changing characters within the file, updating images, renaming files etc.
2) It allows multiple programmers to work together
This is one of the main reasons Git was created, as a way for developers all over the world to work together on the same project without tripping over each other’s changes.
A common way of working with Git is for each developer to work on their own “branch” of the code.
The main branch will often be called master or main.
A developer can then create their own branch, for example if I was working on a new upload user profile image feature I might call this branch upload_user_avatar.
I can then work on this branch locally and as long as I haven’t pushed the branch up (think of this as “uploading” my changes) other developers won’t be able to access this branch.
This branch will have all the changes that were on main branch including anything new I’ve added.
I can push the branch up at any time without impacting the main branch, and this is recommended so that I have a backup of my work.
Once I’m done with my work I can “merge” it back to the main branch (once my team has approved my work) and now those changes will be accessible to everyone through this branch.
3) It retains data integrity
Every time you’re ready to save your changes on a branch you “commit” those changes.
A commit can include a change to a single file or multiple files.
Git will then generate a checksum that will identify that commit - a 40 character SHA-1 (Secure Hashing Algorithm 1) hash.
This hash is a string of hexadecimal characters which includes only a-f and 0-9 characters, and looks like this:
a3389c8de77a4bcf7e232b146cx15515f68702b6
If a single character in the codebase changes, the generated hash will also change and thus Git can track whether something has changed and whether any files are corrupted.
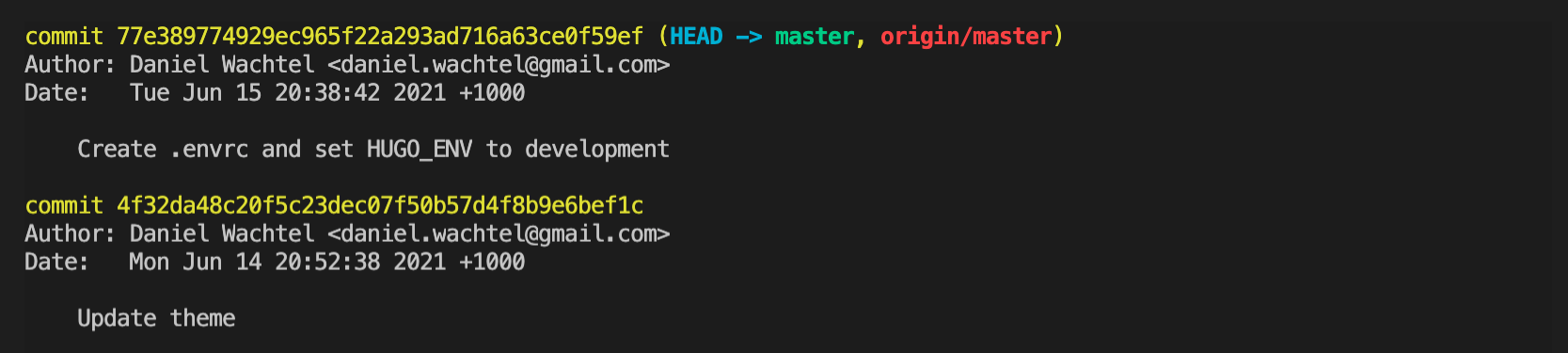 Viewing Git history using the command “git log”
Viewing Git history using the command “git log”
How is Git used?
Although there are graphical interfaces, Git is generally used via the command line interface.
Some typical commands you would type into a terminal to interact with Git look like as follows.
Initializing a new Git repository:
git init
Adding some files so you can commit them:
git add content/my-first-post.html
git add images/awesome-pic.png
Or alternatively add all files and folders in the current directory in one go:
git add .
Next you commit the changes with a human friendly message:
git commit -m "Create first post"
After that you can push the changes up to a remote repository (this is where GitHub and co. come in).
Scenarios where Git can save your life
To put the usefulness of Git into daily context here are a couple of scenarios which most (I’m tempted to say all) developers would have come across:
1) You just broke the main branch
You’ve just added 10,000 lines of new code to your project.
Your automated tests passed, your manual tests passed and nothing broke on staging so you push the code to production.
After the code goes live errors start pouring in.
Woops!
Imagine if you had to revert those changes manually, your users would be stuck with a broken service for ages.
Instead you can revert to the previous working commit (version) deploy that and debug the issue locally without your service having too much downtime.
2) Priorities changed and you’re halfway through a new feature
This is quite common.
Say you’re working on a new feature and a bug has just been discovered.
With version control and branches you can just:
- Stop your current work and commit it to the branch you were on.
- Hop back to the main branch and create a new branch for the bugfix.
- Fix the bug, merge to the main branch.
- Continue with the feature you were working on.
So… what is GitHub and why do you need it?
So now that we know what Git does, what is GitHub?
GitHub is a cloud service that allows you to store your Git repository remotely.
It was launched in 2008 and acquired by Microsoft in 2018 for $7.5 billion.
It is the largest host of source code in the world, at the time of writing it has over 65 million users and over 30 million public repos.
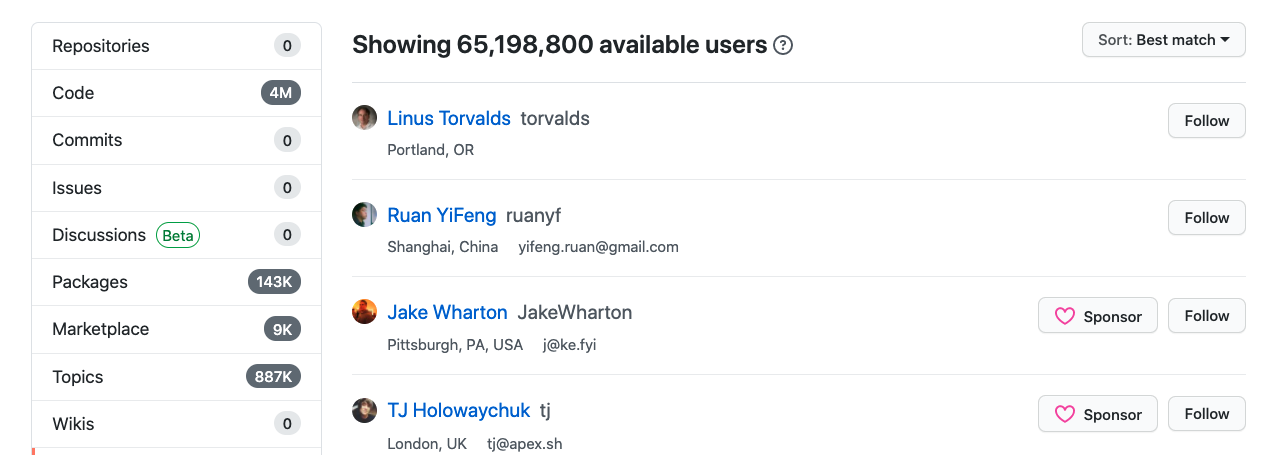 Count of users on GitHub
Count of users on GitHub
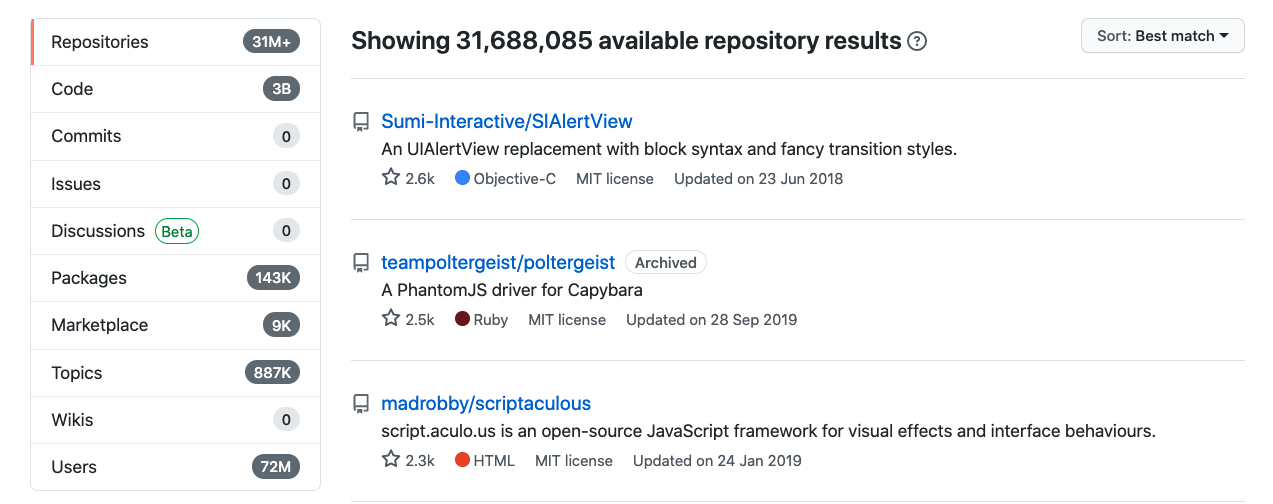 Count of public repositories on GitHub
Count of public repositories on GitHub
What exactly is a remote repository?
A remote repository is a version of your project that is hosted remotely, so not on your own computer but on the internet or a network.
This allows multiple developers to share the same work-flow, pushing and pulling to the same target.
If you didn’t have remote repos it would be extremely inconvenient working on a single project as a team.
Apart from this, a remote repository also serves as a backup for your code in case your laptop or computer suddenly fries.
What else can I do on GitHub?
GitHub is more than just a remote repository, it also:
- Offers a web-based graphical user interface for many Git commands, which makes it more user friendly.
- Allows other GitHub users to open issues and track bug fixes.
- Allows users to create wikis to aid others in using their programs / code.
- Offers different levels of access control, for example private vs public repos, or setting various permission levels for your team members.
- CI (Continuous Integration) features, for example GitHub Actions which let you trigger testing and deployment when certain branches are updated.
- Free hosting for static pages with GitHub pages.
- And more…
 Viewing Git changes via the command line interface
Viewing Git changes via the command line interface
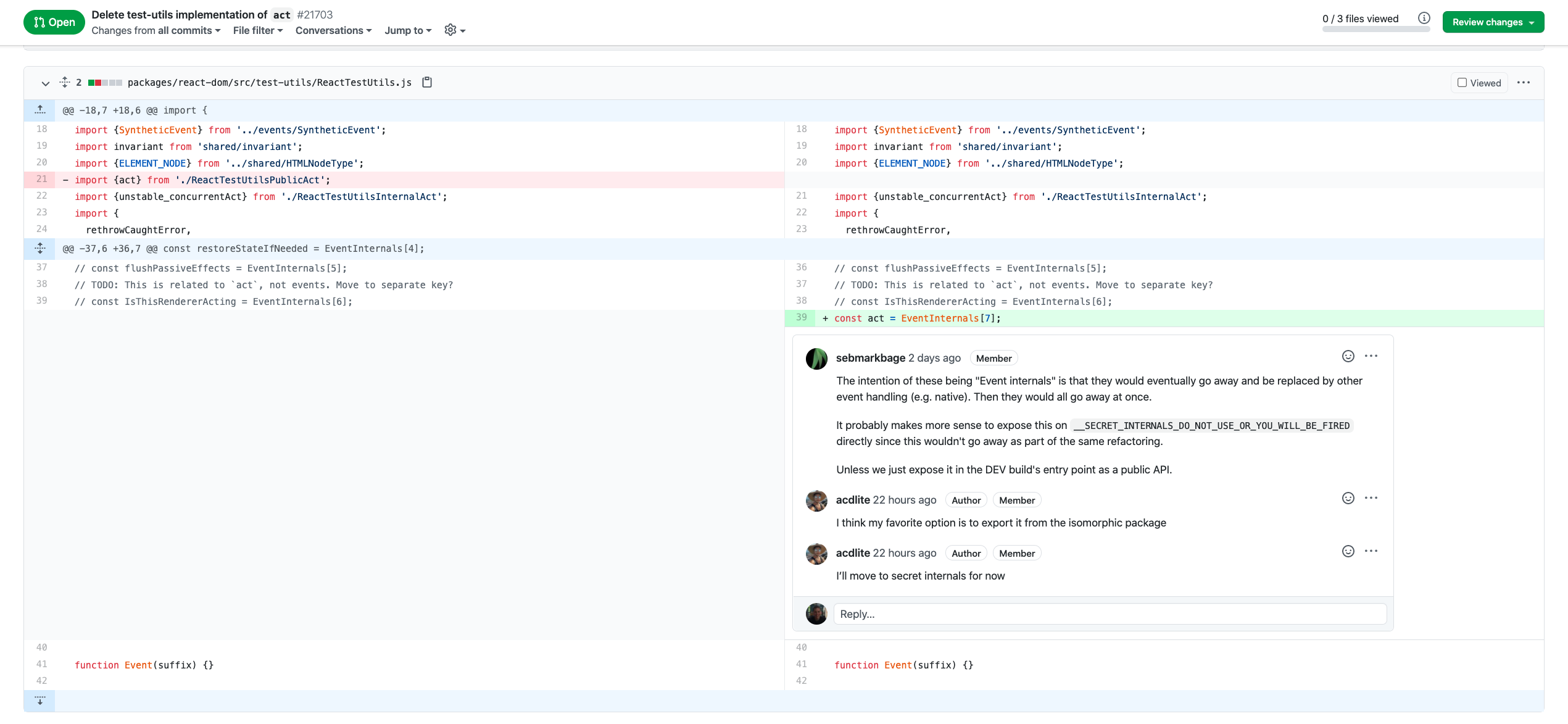 Viewing changes for a pull request on GitHub
Viewing changes for a pull request on GitHub
As seen above the graphical interface is a big help when looking at differences (“diffs”) between branches and has additional features such as commenting (and emojis).
What is GitLab and how does it differ to GitHub?
GitLab is very similar service to GitHub, but doesn’t have as many users with around 30 million registered users according to the company.
It was launched in 2014, 6 years after GitHub.
GitLab offers all the major features that GitHub does, including:
- Allowing users to fork a repo (copy it so they have their own version they can work on).
- Submitting pull requests, known as merge requests in GitLab.
- Publishing wikis, changelogs, issues and bug tracking.
- Continuous integration.
- GitLab pages (same idea as GitHub pages).
- Etc.
One of the main differences between the two services is that GitLab is open source which means you can download the source code from here and self host the service on your own servers or on a cloud provider.
The second key difference is that GitLab offers its own deployment platform built on Kubernetes. With GitHub you would need to use an external platform, like AWS or Heroku and trigger your deploys there.
A few alternatives to GitHub and GitLab
Although these are the two largest players in the field there are alternatives out there, including:
- BitBucket - run by Atlassian who own Trello, Jira, HipChat and Confluence, and offer various integrations between their services.
- SourceForge - an open source service with around 2.1 million users and 500k open source projects.
- Cloud Source Repositories - a service run by Google.
- AWS CodeCommit - a service run by Amazon with a focus on security, it does not allow public repos.
- Gogs - an open source, self-hosted Git service.
- Launchpad - a service by Canonical (developers of Ubuntu) that supports both Git and Bazaar version control systems.
There are a few more services out there, however together with GitHub and GitLab this is quite a selection for source code hosting.
Conclusion
For anyone getting into coding I highly recommend learning to use Git as it is used by teams worldwide.
There are many remote source code repositories like GitHub out there, so once you’ve learned to use one it’s not hard to switch to another.
The first company I worked for used BitBucket, the second used GitHub and it didn’t take long to adapt.
If you don’t have a favourite yet I would recommend learning to use GitHub as it is the most popular choice.
Happy coding!